Zookeeper集群基于Master/Slave的模型
处于主要地位负责处理写操作)的主机称为Leader节点,处于次要地位主要负责处理读操作的主机称为 follower 节点
当进行写操作时,由Master(leader)完成,再同步到其它Slave(follower)节点,而且要求在保证写操作在所有节点的总数过半后,才会认为写操作成功
生产中读取的方式一般是以异步复制方式来实现的。
对于n台server,每个server都知道彼此的存在。只要有>n/2台server节点可用,整个zookeeper系统保持可用。因此zookeeper集群通常由奇数台Server节点组成
官方链接: 下图表示读的比例越高,性能越好
http://zookeeper.apache.org/doc/r3.7.0/zookeeperOver.html
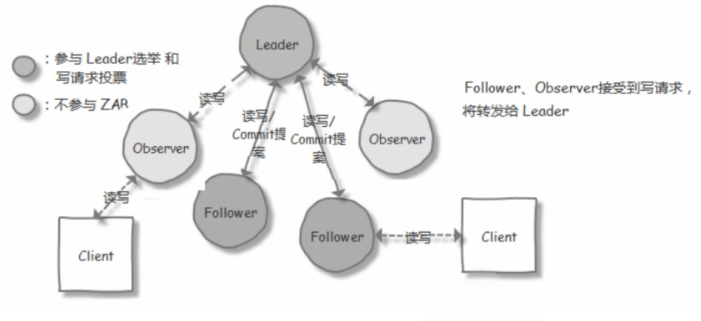

| 序号 | 角色 | 职责描述 |
|---|---|---|
| 1 | 领导者(Leader) | 负责处理写入请求的,事务请求的唯一调度和处理者,负责进行投票发起和决议,更新系统状态 |
| 2 | 跟随(Follower) | 接收客户请求并向客户端返回结果,在选Leader过程中参与投票 |
| 3 | 观察(Observer) | 转交客户端写请求给leader节点,和同步leader状态,和Follower唯一区别就是不参与Leader投票,也不参与写操作的"过半写成功"策略 |
| 4 | 学习者(Learner) | 和leader进行状态同步的节点统称Learner,包括:Follower和Observer |
| 5 | 客户端(client) | 请求发起方 |
1.选举过程
节点角色状态:
LOOKING:寻找 Leader 状态,处于该状态需要进入选举流程
LEADING:领导者状态,处于该状态的节点说明是角色已经是Leader
FOLLOWING:跟随者状态,表示 Leader已经选举出来,当前节点角色是follower
OBSERVER:观察者状态,表明当前节点角色是 observer
1.1选举ID
ZXID(zookeeper transaction id):每个改变 Zookeeper状态的操作都会自动生成一个对应的zxid。ZXID最大的节点优先选为Leader
myid:服务器的唯一标识(SID),通过配置 myid 文件指定,集群中唯一,当ZXID一样时,myid大的节点优先选为Leader
ZooKeeper 集群选举过程:
当集群中的 zookeeper 节点启动以后,会根据配置文件中指定的 zookeeper节点地址进行leader 选择操作,过程如下:
每个zookeeper 都会发出投票,由于是第一次选举leader,因此每个节点都会把自己当做leader 角色进行选举,每个zookeeper 的投票中都会包含自己的myid和zxid,此时zookeeper 1 的投票为myid 为 1,初始zxid有一个初始值0x0,后期会随着数据更新而自动变化,zookeeper 2 的投票为myid 为2,初始zxid 为初始生成的值。
每个节点接受并检查对方的投票信息,比如投票时间、是否状态为LOOKING状态的投票。对比投票,优先检查zxid,如果zxid 不一样则 zxid 大的为leader,如果zxid相同则继续对比myid,myid 大的一方为 leader成为 Leader 的必要条件: Leader 要具有最高的zxid;当集群的规模是 n 时,集群中大多数的机器(至少n/2+1)得到响应并从follower 中选出的 Leader。
心跳机制:Leader 与 Follower 利用 PING 来感知对方的是否存活,当 Leader无法响应PING 时,将重新发起 Leader 选举。当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB(Zookeeper Atomic Broadcast) 协议就会进入恢复模式并选举产生新的Leader服务器。这个过程大致如下:
Leader Election(选举阶段):节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
Discovery(发现阶段):在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
Synchronization(同步阶段):同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后 准leader 才会成为真正的 leader。
Broadcast(广播阶段) :到了这个阶段,Zookeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有
新的节点加入,还需要对新节点进行同步
1.2ZAB 协议介绍
ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在
ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之
间的数据一致性。
1.3ZooKeeper 集群特性
整个集群中只要有超过集群数量一半的 zookeeper工作是正常的,那么整个集群对外就是可用的假如有 2 台服务器做了一个 Zookeeper 集群,只要有任何一台故障或宕机,那么这个 ZooKeeper集群就不可用了,因为剩下的一台没有超过集群一半的数量,但是假如有三台zookeeper 组成一个集群, 那么损坏一台就还剩两台,大于 3台的一半,所以损坏一台还是可以正常运行的,但是再损坏一台就只剩一台集群就不可用了。那么要是 4 台组成一个zookeeper集群,损坏一台集群肯定是正常的,那么损坏两台就还剩两台,那么2台不大于集群数量的一半,所以 3 台的 zookeeper 集群和 4 台的 zookeeper集群损坏两台的结果都是集群不可用,以此类推 5 台和 6 台以及 7 台和 8台都是同理
1.4Zookeeper
ZooKeeper集群中的每个服务器节点每次接收到写操作请求时,都会先将这次请求发送给leader,leader将这次写操作转换为带有状态的事务,然后leader会对这次写操作广播出去以便进行协调。当协调通过(大多数节点允许这次写)后,leader通知所有的服务器节点,让它们将这次写操作应用到内存数据库中,并将其记录到事务日志中。当事务日志记录的次数达到一定数量后(默认10W次),就会将内存数据库序列化一次,使其持久化保存到磁盘上,序列化后的文件称为"快照文件"。每次拍快照都会生成新的事务日志。
2.zookeeper集群部署
官方文档:
https://zookeeper.apache.org/doc/r3.6.2/zookeeperAdmin.html#sc_zkMulitServerSetup
2.1集群规划:
| MyID服务器唯一编号 | 主机名 | 配置清单 | 系统OS | 主机IP |
|---|---|---|---|---|
| 1 | zookeeper-1 | 4CPU/4G内存/120G存储 | ubuntu22.04-server | 172.16.0.180 |
| 2 | zookeeper-2 | 4CPU/4G内存/120G存储 | ubuntu22.04-server | 172.16.0.181 |
| 3 | zookeeper-3 | 4CPU/4G内存/120G存储 | ubuntu22.04-server | 172.16.0.182 |
2.2安装
2.2.1脚本安装3节点
https://9527edu.org/post/198.html
2.2.2手动安装JDK
[root@zookeeper-1:~# apt update && apt -y install openjdk-11-jdk
[root@zookeeper-2:~# apt update && apt -y install openjdk-11-jdk
[root@zookeeper-3:~# apt update && apt -y install openjdk-11-jdk
2.2.3下载apache-zookeeper-3.8.4-bin.tar.gz
[root@zookeeper-1:~# wget -P /usr/local/src https://downloads.apache.org/zookeeper/stable/apache-zookeeper-3.8.4-bin.tar.gz
[root@zookeeper-2:~# wget -P /usr/local/src https://downloads.apache.org/zookeeper/stable/apache-zookeeper-3.8.4-bin.tar.gz
[root@zookeeper-3:~# wget -P /usr/local/src https://downloads.apache.org/zookeeper/stable/apache-zookeeper-3.8.4-bin.tar.gz
2.2.4准备配置文件,配置好以后拷贝到其他节点上面
#三个节点都要创建数据目录
[root@zookeeper-1:~# mkdir /usr/local/zookeeper/data
#基于模板配置文件生成配置文件
[root@zookeeper-1:~# cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
#修改配置文件
[root@zookeeper-1:~# vim /usr/local/zookeeper/conf/zoo.cfg
#配置文件内容
[root@zookeeper-1:~# grep -v "\^\#" /usr/local/zookeeper/conf/zoo.cfg
tickTime=2000 #服务器与服务器之间的单次心跳检测时间间隔,单位为毫秒
initLimit=10 #集群中leader 服务器与follower服务器初始连接心跳次数,即多少个 2000 毫秒
syncLimit=5 #leader 与follower之间连接完成之后,后期检测发送和应答的心跳次数,如果该follower在设置的时间内(5*2000)不能与leader 进行通信,那么此 follower将被视为不可用。
dataDir=/usr/local/zookeeper/data #自定义的zookeeper保存数据的目录
clientPort=2181 #客户端连接 Zookeeper 服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求
maxClientCnxns=128 #单个客户端IP 可以和zookeeper保持的连接数
autopurge.snapRetainCount=3 #3.4.0中的新增功能:启用后,ZooKeeper 自动清除功能,会将只保留此最新3个快照和相应的事务日志,并分别保留在dataDir 和dataLogDir中,删除其余部分,默认值为3,最小值为3
autopurge.purgeInterval=24 #3.4.0及之后版本,ZK提供了自动清理日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是 0,表示不开启自动清理功能
#格式: server.MyID服务器唯一编号=服务器IP:Leader和Follower的数据同步端口(只有leader才会打开):Leader和Follower选举端口(L和
F都有)
server.1=172.16.0.180:2888:3888
server.2=172.16.0.181:2888:3888
server.3=172.16.0.182:2888:3888
#如果添加节点,只需要在所有节点上添加新节点的上面形式的配置行,在新节点创建myid文件,并重启所有节点服务即可
[root@zookeeper-1:~# scp /usr/local/zookeeper/conf/zoo.cfg 10.0.0.102:/usr/local/zookeeper/conf/
[root@zookeeper-1:~# scp /usr/local/zookeeper/conf/zoo.cfg 10.0.0.103:/usr/local/zookeeper/conf/
2.2.5在各个节点生成ID文件
[root@zookeeper-1:~# echo 1 > /usr/local/zookeeper/data/myid
[root@zookeeper-2:~# echo 2 > /usr/local/zookeeper/data/myid
[root@zookeeper-3:~# echo 3 > /usr/local/zookeeper/data/myid
2.2.6各服务器启动 Zookeeper
#注意:在所有三个节点快速启动服务,否则会造成集群失败
[root@zookeeper-1:~# zkServer.sh start
[root@zookeeper-2:~# zkServer.sh start
[root@zookeeper-3:~# zkServer.sh start
#注意:如果无法启动查看日志
[root@zookeeper-node1 ~]#cat /usr/local/zookeeper/logs/zookeeper-root-server-zookeeper-node1.wang.org.out
2.2.7查看集群状态
#follower会监听3888/tcp端口
[root@zookeeper-1 ~]#zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@zookeeper-1 ~]#ss -ntl |grep 888
LISTEN 0 50 [::ffff:10.0.0.101]:3888 *:*
#只有leader监听2888/tcp端口
[root@zookeeper-2 ~]#zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@zookeeper-2 ~]#ss -ntl|grep 888
LISTEN 0 50 [::ffff:10.0.0.102]:3888 *:*
LISTEN 0 50 [::ffff:10.0.0.102]:2888 *:*
[root@zookeeper-3 ~]#zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@zookeeper-node3 ~]#ss -ntl|grep 888
LISTEN 0 50 [::ffff:10.0.0.103:3888